Starting a new job is a lesson in how much of work is just slang. The acronyms in your first standup. The product names that sound made up. The customer references everyone clearly recognises while you make a mental note to Google later. And one of your new colleagues kindly soothes you. "Don't worry, it'll take a few weeks to get your head around all the internal talk."
They're right. It does. Every company has its own language. The product names that don't follow English spelling rules. The acronyms only your team uses. The customer names that get mangled the first time anyone hears them on a call.
Flickr, not Flicker. 20VC, not Twenty VC. Anthropic, not Anthropik. The shorthand your CS team uses for that one feature nobody outside the building has heard of. The internal codename for the project that's still six months from launch.
These aren't edge cases. They're the actual vocabulary of your business. And they're the first things that go wrong when AI tries to make sense of a call.
The problem isn't accuracy in general. Modern speech-to-text is good enough that most words land where they should. The problem is that the words it gets wrong are almost always the ones that matter most. Your company name. Your product. Your competitors. The contact whose surname is spelled a way nobody guesses on the first try. Everything else can be 99% accurate and the call notes still feel wrong, because the proper nouns, the things that make the conversation specifically about your business, are the things the model is least likely to know.
We saw this happen with our beta users almost immediately. A CSM mentions a customer's product on a call. The transcript spells it three different ways across the same conversation. The CRM record gets updated with one of those three. Two weeks later someone searches for the right spelling and finds nothing. The knowledge was captured. The knowledge wasn't findable.
This is the pattern we keep coming back to. Capture is necessary but it isn't sufficient. If what gets captured doesn't reflect what was actually said, all we've done is scale a different kind of mess.
So we built Language.
Language is the place where you tell Soda what your business actually sounds like. Company names, product names, customer names, internal acronyms, the words that are specific to your world. You add them once, and from that point on Soda treats them as known terms. Calls get transcribed correctly. CRM records use the right spelling. Search returns what you're actually looking for.
But the bigger shift is that you don't really have to add things at all. Language learns as you go. When you join a call Soda picks up the person's name and the spelling they use for it. The vocabulary builds itself in the background, the same way the rest of Soda does.
You'll see new terms appear as Soda spots them. Correct anything that's off, add your own, or leave it to keep building in the background. After a few weeks of normal use, your company's full vocabulary is already there without anyone having sat down to write it out.
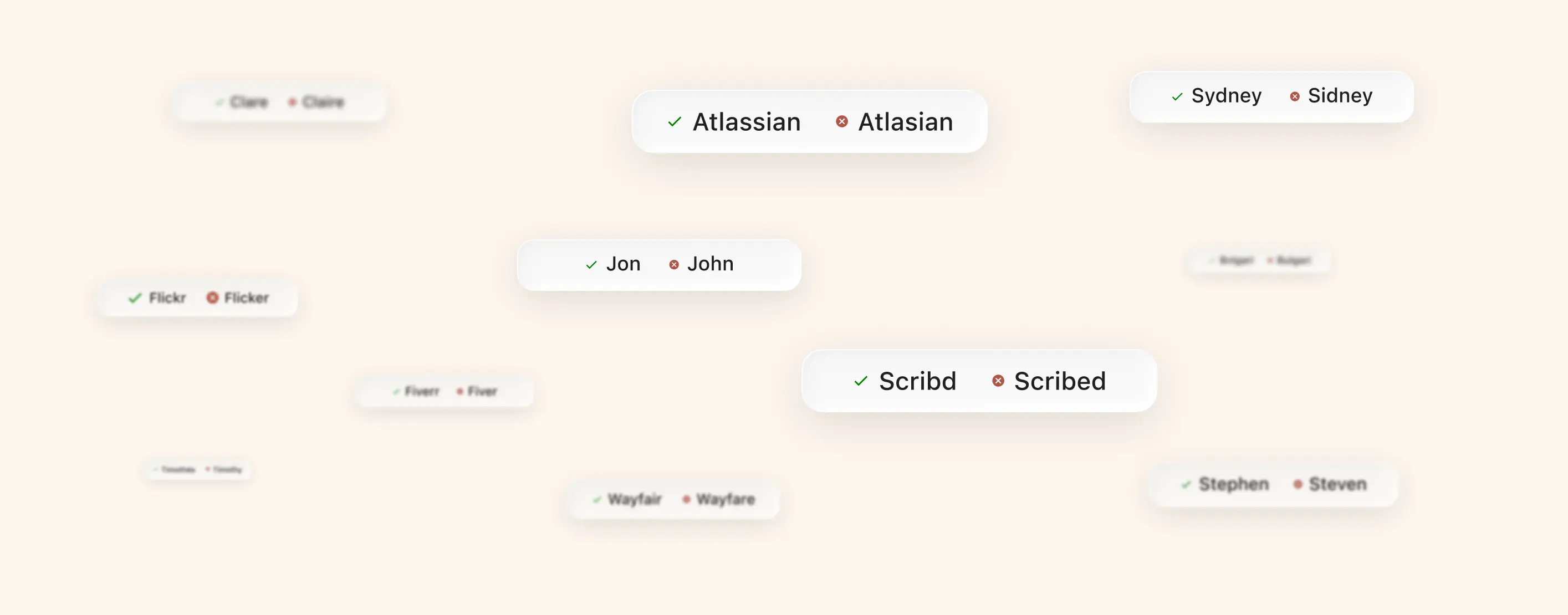
Language also learns from corrections. If you fix a misspelling in a Soda record, that correction propagates backwards too. Old transcripts get updated. Past CRM entries get cleaned up. The next time anyone mentions the same term, Soda already knows.
This is a small feature. It looks like a list of words on a settings page. But it changes whether your captured knowledge is actually usable, or just nearly-right in a way that costs you a few minutes every time you go looking for something.
Capture without effort only works if what gets captured reflects what actually happened. Language is how we make sure it does.
Soda is currently in private beta. If your company has its own vocabulary and you're tired of seeing it spelled wrong, join the waitlist.